Recommendation Engines Overview
In these days, for customers there are so many alternatives to use a mobile app for a specific task and most of them work well in terms of functionality. What differs in terms of the customer is the experience you gave them. The most powerful influence that you can give to the customer is making them feel special. To do this you must provide a personalized experience for each customer. Recommendation Engines are exactly developed on that purpose. Today everything we need can be easily accessible from the internet markets. On the contrary, accessibility comes with a plenty of options problem, in other words, as the more products becomes available it is harder to choose what you want from this plenty of options. Recommender Systems come to show in this time by pairing relevant products with relevant people.
In a mobile app, user actions are stored in a server. As a user uses the mobile app, his data growing up by the company’s point of view. But the data grow rapidly and to use data effectively to rule the actions, it must be transformed truly by Data Engineers. When it comes to a Recommendation System, the idea is similar, as the items in an app grows, the items must be filtered for the specific user respectively. Mainly there are two approaches for these candidates to be generated : Content Based Filtering and Collaborative Filtering.
1) Content Based Filtering
Content based approach uses additional information of users and items for predicting new items to the customer. In this approach the goal is based on past item preferences, recommending similar items to the user. The similarity is constructed between the items but users. For example, for Youtube, if you are watching cat videos, the model can recommend you new cat videos based on your previous watching history.
The model gets the features of the items and map them to an lower dimensional embedding in a multi-dimensional space. Then train a model with a cost function to correct these representations using their previous user-item interactions. I will use Google’s example to explain this approach[1]. Take the apps in a Google Play Store. In the figure there are some feature matrix of apps. For the sake of simplicity features are binary {0,1}.
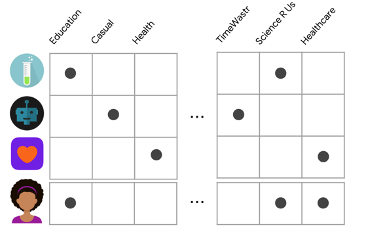
The features are not just categories it can be all kind of information that is useful to describe an item. At the same time users has a representation in the same feature space. Some features could be explicitly provided by the user himself e.g. by adding some attributes to their favorites. Some other features could be implicit like when you install another app with the same category. Then to recommend relevant items, it must be based on a similarity measure. One of the similarity measure is dot product. By dot product of a user and item, it can be determined the similarity between them. Thus by dot product all the items with a user and ranking them based on their score, you can get recommendations for that user. the disadvantages of this approach is new users with unseen features will logically suffer from bad recommendations. But as soon as this new attribute trained and acknowledged by the model properly it will be auto-corrected. Another disadvantage is the model does not make use of the personal similarities between users.
2) Collaborative Filtering
In contrast to the Content Based Filtering, Collaborative Filtering is solely based on the previous user-item interactions. In this approach the goal is finding similarity between users to recommend items. The model assumes a generative relation which explains user-item interaction and tends to find this relation. Basically, the idea that lies behind the Collaborative Filtering is that past interactions is sufficient to detect similar users and predict choices of users. Collaborative filtering can recommend an item to a user based on interests of a similar user. Also the embeddings of users can be learned directly without relying on human-generated features. For example, lets consider Google’s example again:

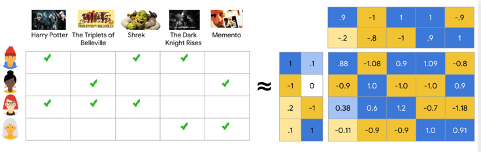
In this movie recommendation example each row of a matrix represents a user and each column represents the films. based on other interactions the goal is to find the read box which is the whether the third user likes Shrek movie. This comes with a memory problem because this matrix will be so sparse in other words there would be so many empty entries of matrix and machines come with a restricted memories. As the model scaled up. it becomes a huge problem.
To solve this problem, there is a popular linear algebra technique called matrix factorization. Matrix factorization as represented in the Figure 3 decompose a matrix A to its factors U and V which gives A = U x VT . Matrix factorization basically gives more compact representation than a whole matrix. By this Collaborative Filtering problem converts to a Matrix factorization problem and also by decomposing the matrix we can fill the empty entries by this decomposition. The objective becomes minimize the square of the errors over all pairs of interactions. It can be easily solved by gradient descent algorithm. The advantage of this approach is we do not need any side information about users or items because the embeddings learned automatically. The drawback of this approach is that we cannot handle the fresh users or items. This is called cold-start problem. Besides we cannot make use of information about items or users. Maybe this information can work better than the previous.
3) Hybrid Factorization Machine Models
In 2010 Steffen Rendle [5] introduced a model called Factorization Model combining two of the approaches that is mentioned above. I will not go into detail about Hybrid FM Model but we can get the idea if we look at the equation:
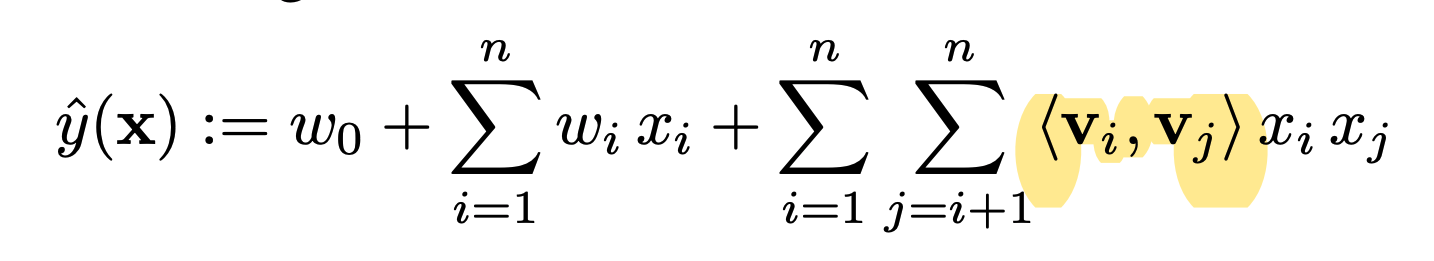
The equation separated in two parts: first is regression part which is included the user and item features to the model and the second part is straightforward matrix factorization part like in the Collaborative Filtering.
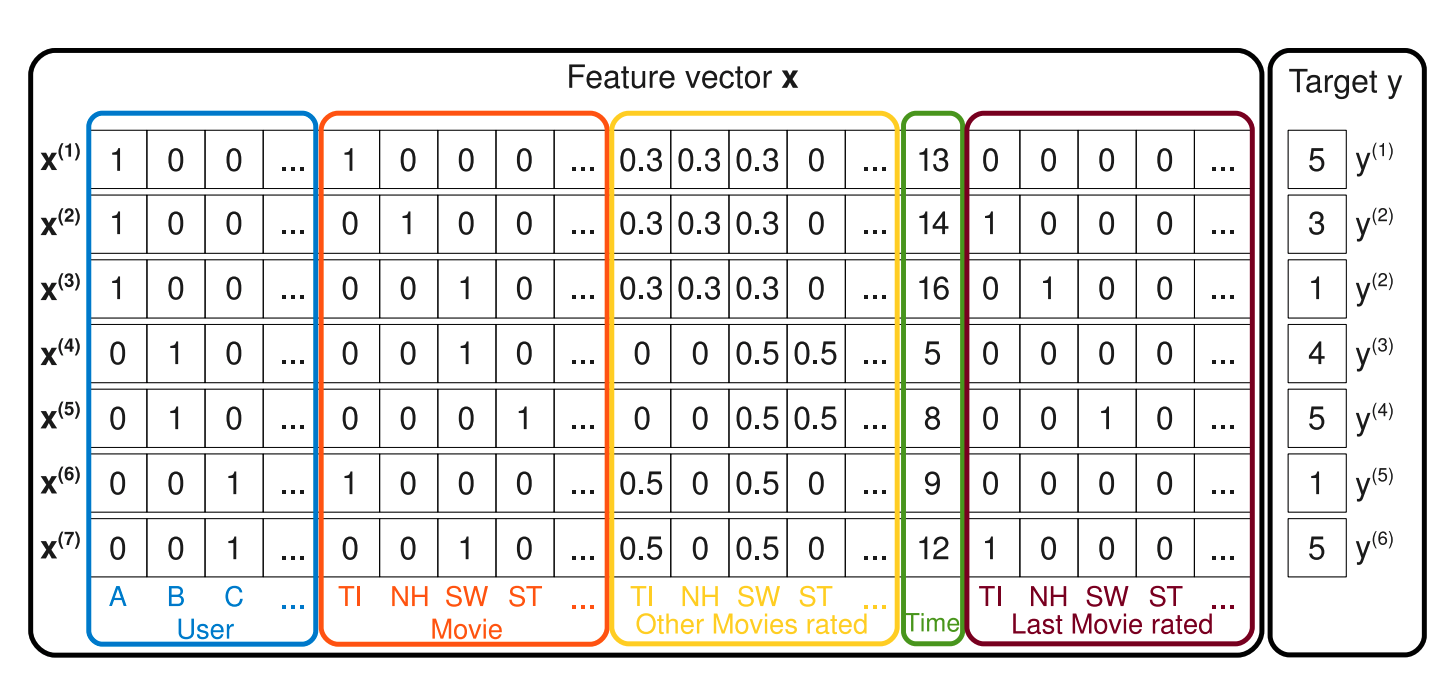
The data format is like concatenated vectors of all features every row and this gets mapped into target vector y. Sparse features that represent user, sparse features that represents item and side information about user and item all are part of vector x. While regression part handles all data like in the content based filtering, Matrix factorization part finds relation between the feature blocks.
In this post we have examined the general overview of the recommendation engines from the content based filtering to the collaborative filtering and a newer approach which combines two perspectives.
Thank you for reading.
References
[1] https://developers.google.com/machine-learning/recommendation/content-based/basics
[2] https://developers.google.com/machine-learning/recommendation/images/Matrix1.svg
{kind=link}
[3] https://developers.google.com/machine-learning/recommendation/images/2Dmatrix.svg
{kind=link}
[4] https://developers.google.com/machine-learning/recommendation/images/Matrixfactor.svg
{kind=link}
[5] S. Rendle, “Factorization Machines,” 2010 IEEE International Conference on Data Mining, 2010, pp. 995-1000, doi: 10.1109/ICDM.2010.127.